11.단어 및 불용어 2차정제
💡목표
- 불용어 처리방법 3가지 활용하기. 1. 정규식을 이용해 알파벳만 남기기
2. 필요한 특수문자/숫자 제거하기
3. 내 stopwords 거르고 일부 단어 정제/통합
1. 불용어란?
텍스트 문장에서 큰 의미가 없는 단어를 불용어(Stopword)라고 합니다. 불용어 처리는 텍스트분석에서 가장 중요한 전처리 과정 중 하나로 I, you, it, is, am 과 같이 텍스트 분석시에 크게 의미 없는 단어를 제거하는 과정을 말합니다.
예를 들어, 회사의 회의을 통해 자주 쓰이는 단어를 분석하여 부서의 분위기를 파악하기 위한 텍스트 분석을 진행한다고 하자.
- 회의주제 : 소비자 트렌드에 맞춘 마케팅 방법
- 일시 : 2023년 04월 09일 14:00~16:00
- 장소 : 제2회의실
- 회의내용 : 주로 20~30대의 소비자층을 가지고 있으므로 SNS을 활용한 방법을 주로 홍보를 진행한다. 이번 상품들의 재료가 저번과 다른 친환경적인 재료를 사용한 점을 부각시켜 소비자의 건강에도 해를 끼치지 않는다는 부분을 강조한다.
이와 같은 텍스트문이 있을때 어떠한 부분이 불용어일까?
-
‘2023년 04월 09일’ 숫자
-
’ : ‘ 기호
-
‘은,는,의,를’ 조사
-
‘들’,’적인’ 접미사
위와 같은 부분이 계속 반복되어 큰 의미를 가지고 있지 않는 불용어 인 것이다. 이러한 불용어는 전처리 과정을 거치면서 제거해줘야만 의미있는 텍스트 분석이 가능하다.
2. 불용어처리 방법
실습준비(패키지 설치)
# pip install wordcloud #No module named 'wordcloud' 오류시에 실행시키기
import pandas as pd
import numpy as np
from nltk.tokenize import word_tokenize #토큰화
from nltk.corpus import stopwords #불용어
from nltk.stem import PorterStemmer, WordNetLemmatizer #어간추출
from sklearn.feature_extraction.text import CountVectorizer
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
# wos_ai_.csv 파일에서 ABSTRACT 열만 data파일에 저장
data=pd.read_csv('wos_ai_.csv',encoding='euc-kr').ABSTRACT
실습파일인 wos_ai_.csv 파일을 사용하였고_ wos_ai.csv 파일에서 텍스트분석에 필요한 ABSTRACT 열만 data에 저장 하였습니다.
여기서는 nltk.corpus 의 stopwords 불용어와 wordcloud 의 STOPWORDS 불용어 2가지를 불러와서 사용할 예정입니다. wordcloud의 불용어 라이브러리는 대문자임을 유의해주세요.
nltk는 자연어처리를 위한 패키지로 전처리를 위한 라이브러리만 불러왔습니다.
방법1) 정규식을 이용해 알파벳만 남기기
* 정규식이란?
-
정규 표현식으로 특정한 규칙을 가진 문자열의 집합을 표현하는 데 사용하는 형식 언어이다.
-
특정 검색 패턴에 대한 하나 이상의 일치 항목을 검색해 텍스트에서 정보를 추출하는데 매우 유용하다.
-
불용어 처리에서 [ 특수문자, 숫자, 기호 ]를 제거한 [ 알파벳 ]만 추출하는 등 유용하게 사용가능하다.
특수문자, 숫자, 기호를 알파벳 빼고 전부 제거하기 위해 정규식(정규표현식)을 사용해보겠습니다. 정규표현식을 사용하기 위해 내장 패키지인 re 를 불러왔습니다.
import re #정규식 불러오기
doc_set = [] #전처리 전 텍스트 저장을 위한 리스트
words = [] #전처리 후 텍스트 저장을 위한 리스트
for doc in data :
if type(doc) != float :
doc_set.append(doc.replace("_"," "))
반복문을 통해서 숫자가 아닌 문자만 doc_set 리스트에 _를 공백처리해서 넣어주었고, type(변수)는 변수의 데이터타입을 확인하는 함수로 data의 단어가 실수(float)인지 확인하고 아니면(!=) doc_set.append(doc.replace(“”,” “))를 시행하도록 하였습니다.
list.append(변수)는 변수를 list에 추가시키는 함수로 doc_set 리스트에 doc.replace(“_”,” “)를 추가하였습니다.
문자열.replace(old,new,[count]) 함수는 count번까지 old를 new로 바꾸는 함수로 여기서 “_” 구분자를 공백으로 처리하도록 하였습니다. (ex: new_things -> new things)
stopWords = set(stopwords.words('english'))
stemmer=PorterStemmer()
nltk.corpus 의 불용어 stopwords를 영어단어를 set() 집합 형태로 stopWords 변수에 할당하고 PorterStemmer 는 어간추출을 위한 명령어로 해당 명령어를 실행시키기 위해 stemmer에 할당하였습니다.
어간추출은 같은 의미이지만 다양한 형태로 쓰인 단어를 하나의 어간으로 만들어 중복된 단어가 생기지 않도록 하는 전처리 과정 중 하나 입니다. (어간추출의 예 : networking -> network , called -> call )
for doc in doc_set:
noPunctionWords = re.sub(r"[^a-zA-Z]+"," ",str(doc)) #알파벳만 출력
tokenizedwords = word_tokenize(noPunctionWords.lower()) #소문자처리, 토큰화
stoppedwords=[w for w in tokenizedwords if w not in stopWords] #불용어처리
stemmedwords=[stemmer.stem(w) for w in stoppedwords] #어간추출
words.append(" ".join(stemmedwords)) #단어들을 공백으로 합쳐줌
doc_set에 있던 텍스트가 doc에 할당되어 반복문으로 전처리 한 부분을 하나씩 살펴보자면
-
불용어처리
re 패키지의 sub()함수를 사용해서 불용어인 기호와 숫자를 처리하였습니다.
re.sub(r”[^a-zA-Z]+”,” “,str(doc)) 구문을 살펴보자면 a-zA-Z는 모든 알파벳을 의미하고, 여기에 ^를 추가한 건 not과 같이 아니라는 의미입니다.
이를 []로 묶고 +를 붙여 ‘ ‘ 전체로 묶은 후에 r을 붙여주는 이유는 r이 문자 그대로 판단하라는 의미로 \ 를 ‘\’ 문자로 인식하라는 의미입니다.
즉, doc를 문자열(str)로 바꾼 후 모든 알파벳을 제외하고 “ “(공백)으로 바꾸라는 의미인 것입니다. -
토큰화
알파벳만 추출된 단어를 noPunctionWords에 할당하고 이를 소문자처리(.lower())한 후에 토큰화 시키는 구문이 word_tokenize(noPunctionWords.lower()) 입니다. -
불용어처리
토큰화된 단어가 tokenizedwords 되어 불용어처리를 위해 [w for w in tokenizedwords if w not in stopWords] 구문을 거치는데 이는 변수(tokenizedwords)의 단어(w)가 불용어(stopWords)가 아니라면(not in) stoppedwords에 반환해준다는 의미 입니다. -
어간추출
이렇게 불용어를 거친 stoppedwords의 단어가 하나씩 어간추출화(stemmer.stem(w)) 된 후에 stemmedwords 변수에 할당되어지고 이를 공복(“ “)으로 합쳐주는 함수 join을 통해 word 리스트로 저장(.append)해주게 됩니다.
텍스트가 반복문을 거치면서 어떻게 바뀌는지 살펴보면,
| 반복문 내 변수명 | 형태 |
|---|---|
| doc_set (전처리 전) |
[‘The rapid growth of social networking usage has initiated a new business called C2C s-commerce which has opened a novel opportunity for SNS rs to conduct commercial activities among members.’] |
| noPunctionWords (알파벳출력) |
‘The rapid growth of social networking usage has initiated a new business model called C C s commerce which has opened a novel opportunity for SNS users to conduct commercial activities among members’ |
| tokenizedwords (토큰화) |
[‘the’, ‘rapid’, ‘growth’, ‘of’, ‘social’, ‘networking’, ‘usage’, ‘has’, ‘initiated’, ‘a’, ‘new’, ‘business’, ‘model’, ‘called’, ‘c’, ‘c’, ‘s’, ‘commerce’, ‘which’, ‘has’, ‘opened’, ‘a’, ‘novel’, ‘opportunity’, ‘for’, ‘sns’, ‘users’, ‘to’, ‘conduct’, ‘commercial’, ‘activities’, ‘among’, ‘members’] |
| stoppedwords (불용어처리) |
[‘rapid’, ‘growth’, ‘social’, ‘networking’, ‘usage’, ‘initiated’, ‘new’, ‘business’, ‘model’, ‘called’, ‘c’, ‘c’, ‘commerce’, ‘opened’, ‘novel’, ‘opportunity’, ‘sns’, ‘users’, ‘conduct’, ‘commercial’, ‘activities’, ‘among’, ‘members’] |
| stemmedwords (어간추출) |
[‘rapid’, ‘growth’, ‘social’, ‘network’, ‘usag’, ‘initi’, ‘new’, ‘busi’, ‘model’, ‘call’, ‘c’, ‘c’, ‘commerc’, ‘open’, ‘novel’, ‘opportun’, ‘sn’, ‘user’, ‘conduct’, ‘commerci’, ‘activ’, ‘among’, ‘member’] |
| words (전처리 완료) |
[‘rapid growth social network usag initi new busi model call c c commerc open novel opportun sn user conduct commerci activ among member’] |
이러한 처리과정을 거쳐 전처리가 완료된 words의 형태를 가지게 됩니다.
전처리된 words를 한눈에 살펴보기 위해 wordcloud를 통해 시각화 해보겠습니다.
cv=CountVectorizer(max_features=100,stop_words='english').fit(words) #다시한번토큰화
dtm = cv.fit_transform(words)
words = cv.get_feature_names_out()
count_mat=dtm.sum(axis=0)
count_mat
count=np.squeeze(np.asarray(count_mat))
word_count=list(zip(words,count))
word_count
word_count=sorted(word_count,key=lambda x:x[1],reverse=True)
stopwords=set(STOPWORDS)
wc = WordCloud(background_color='black',stopwords=stopwords,width=800,height=600)
cloud=wc.generate_from_frequencies(dict(word_count))
plt.figure(figsize=(12,9))
plt.imshow(cloud)
plt.axis('off')
plt.show()
btm 자료형태로 만들어 이를 시각화하는 내용은 저번 업로드 때 상세히 다뤘으므로 넘어가겠습니다.
방법2) 필요한 특수문자/숫자 제거하기
data=pd.read_csv('wos_ai_.csv',encoding='euc-kr').ABSTRACT
import re #정규식 불러오기
doc_set = [] #전처리 전 텍스트 저장을 위한 리스트
words = [] #전처리 후 텍스트 저장을 위한 리스트
for doc in data :
if type(doc) != float :
doc_set.append(doc.replace("_"," "))
stopWords = set(stopwords.words("english"))
stopWords을 만드는 과정까지는 위와 동일하게 실행시켜주세요.
이번에는 re.sub 구문을 활용해서 원하는 특수문자만 없어지도록 처리해보겠습니다.
stemmer=PorterStemmer()
for doc in doc_set:
noPunctionWords = re.sub(r"[()\"#/@;:<>{}`+=~|.!?,]"," ",str(doc)) #알파벳만 출력
tokenizedwords = word_tokenize(noPunctionWords.lower()) #소문자처리, 토큰화
stoppedwords=[w for w in tokenizedwords if w not in stopWords] #불용어처리
noDigitWords= [w for w in stoppedwords if not w.isdigit()] #숫자처리
stemmedwords=[stemmer.stem(w) for w in noDigitWords] #어간추출
words.append(" ".join(stemmedwords)) #단어들을 공백으로 합쳐줌
-
원하는 기호 처리 : 위에서 [^a-zA-Z]을 통해 모든 알파벳만 제외시켰다면, 이번에는 ()[]\/@:;.!? 등 원하는 기호를 [] 괄호 안에 넣어 공백(“ “)으로 바꿔주었습니다.
이러한 방법을 이용하면 전처리가 되지 않았던 기호를 확인해 추가하는 방식으로 사용할 수 있습니다. -
숫자 처리 : noDigitWords= [w for w in stoppedwords if not w.isdigit()
아까와 다르게 이번엔 숫자를 처리하는 부분을 re.sub()으로 주지 않았기 때문에 for문을 리스트함수식으로 나타내었습니다.
stoppedwords의 단어(w)가 숫자가 아니라면(if not w.isdigit()) 반환하라는 의미로 숫자처리 되어 noDigitWords에 반환됩니다. 여기서 .isdigit를 사용하면 숫자는 true로 숫자 외엔 false로 반환되기 때문에 not을 붙여 문자가 true로 반환되도록 하였습니다.
방법3) 필요한 특수문자/숫자 제거하기
불용어 처리 시에 사용자가 원하는 특수문자/숫자 또는 문자도 있는데 이때는 사용자가 직접 엑셀파일을 만들어 사용할 수 있습니다.
이번 불용어처리 방법에서 사용된 엑셀파일은 아래 링크의 웹사이트에서 가져온 불용어를 엑셀파일(stopwordsEN.csv)로 만들어 적용하였습니다.
SET = pd.read_csv('stopwordsEN.csv',encoding='utf-8')
stopWords=set(SET)
엑셀파일을 켜서 원하는 불용어를 처리하고 또 다시 불러오는 작업을 해도 괜찮지만 번거롭기 때문에 반복문을 통해서 일부 단어를 정제하는 반복문을 구현하였습니다.
data=pd.read_csv('wos_ai_.csv',encoding='euc-kr').ABSTRACT
import re #정규식 불러오기
doc_set = [] #전처리 전 텍스트 저장을 위한 리스트
words = [] #전처리 후 텍스트 저장을 위한 리스트
for doc in data :
if type(doc) != float : #일부 단어 정제/통합
doc = doc.replace("model","")
doc = doc.replace("data","")
doc = doc.replace("use","")
doc = doc.replace("algorithm","")
doc = doc.replace("3-D","3D")
doc = doc.replace("threeD","3D")
doc_set.append(doc.replace("_"," "))
- doc.replace(“a”,”b”) : a 문자를 b로 바꾼다. ex: apple -> bpple
이렇게 replace 구문을 활용하면 같은 의미의 단어도 한 단어로 변경이 가능합니다. “3-D”, “threeD”,”three-D” 모두 같은 단어를 의미하지만 다른 표현방식일 때 replace 함수를 활용해 모두 “3D” 같은 단어로 변경하여 전처리하면 유용합니다.

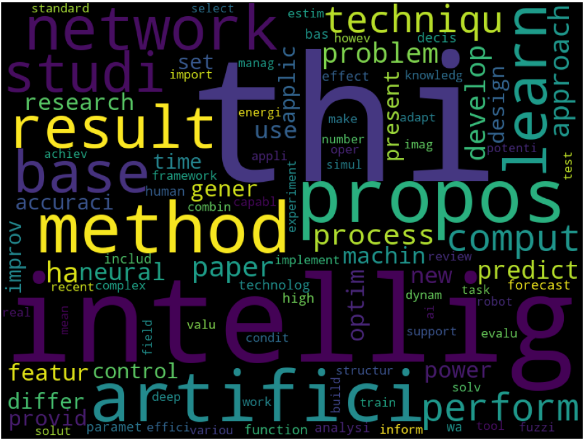
- 불용어 처리 전 –> 불용어 처리 후
사진과 같이 시각화를 통해서 의미없이 많이 쓰이는 단어를 제외시켜서 확인해보니 다양한 단어들을 확인할 수 있게 되었습니다. 이처럼 결과를 확인하면서 필요없는 단어는 계속 정제해내는 작업이 텍스트분석 전에 필요한 것을 알 수 있습니다.
댓글남기기