12.단어 연관분석과 Word Network
💡목표
- IDF에 대해 이해하기.
- DTM자료를 통해한 상관분석 진행하기.
- TTM자료 변환 후 네트워크 분석 진행하기.
1. TF와 TF-IDF란 ?
-
TF-IDF는 Term Frequency - Inverse Document Frequency의 줄임말
-
TF(단어 빈도, term frequency)는 특정한 단어가 문서 내에 얼마나 자주 등장하는지를 나타내는 값이다.
-
TF-IDF는 TF와 IDF를 곱한 값으로 점수가 높은 단어일수록 다른 문서에는 많지 않고 해당 문서에서 자주 등장하는 단어이다. (특정한 문서에서 많이 언급된 단어 일수록 점수가 높다.)
-
DF(문서 빈도, document frequency)의 역수를 IDF(역분서 빈도, inverse document frequency)라고 함
분석을 할때 몇 단어에 집중되는 경향이 있다. 연구주제에 따라 검색하게 될 때 주제와 관련된 단어가 수치가 상당히 높아 편향되는 결과를 야기시킨다. 그래서 가중치를 두기 위한 방법으로 TF-IDF를 사용한다.
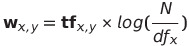
N = 문서의 수
df = x번째 단어가 전체 문서 중 나타난 문서의 수
tk = x번째 단어가 y번째 문서에 나타난 수
w = y번째 문서의 x번째 단어의 IDF
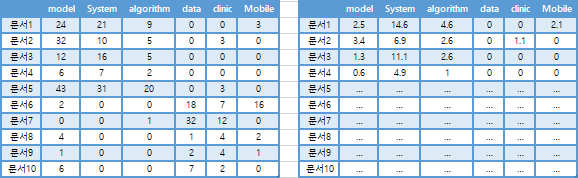
문서1 - model 에 해당하는 IDF를 구해보면 24*log(10/9) = 2.5 이다.
여기서 df는 model이 10개의 문서 중 문서7을 제외한 9개의 문서에 나타났으니 9이다.
문서1 - model 의 IDF는 2.5인 반면 문서1 - algorithm은 9번 밖에 나타나지 않았는데 4.6으로 model의 IDF보다 높다. 왜냐하면 10개의 문서 중에 6번 나타났기 때문이다. 이를 통해 IDF가 특정문서에 많이 언급될 수록 높은 수치를 가지는 것을 확인할 수 있다.
실습준비(패키지 불러오기)
import pandas as pd #데이터 구조
import numpy as np #데이터 구조
from nltk.tokenize import word_tokenize #토큰화
from nltk.corpus import stopwords #불용어
from nltk.stem import PorterStemmer #어간추출
import re #정규표현식(불용어처리)
from sklearn.feature_extraction.text import CountVectorizer #TF파일
import matplotlib.pyplot as plt #데이터 시각화
11장에서의 불러왔던 패키지와 동일하게 불러와줍니다.
data=pd.read_csv('wos_ai_.csv', encoding='euc-kr').ABSTRACT
wos_at_.csv 데이터의 ABSTRACK 열만 추출해서 불러들입니다.
words = [] #전처리 후 단어를 저장하기 위한 리스트
words_joined = [] #전처리된 단어를 문장으로 저장하기 위한 리스트
11장에서는 단어로 토큰화된 텍스트들을 바로 join해서 words에 넣어주었는데 이번에는 별도의 저장공간으로 만들어줍니다.
데이터전처리
stopWords = set(stopwords.words("english"))
stemmer = PorterStemmer()
불용어 처리를 위해 nltk 패키지의 stopwords 불용어 사전 불러와 변수에 저장해줍니다.
그리고 어간 처리를 해주는 PorterStemmer()를 stemmer 변수에 저장해줍니다. 별도 변수로 저장하는 이유는 나중에 명령문을 사용할때 너무 길어지기 때문에 정리해주기 위해 명령문을 변수에 짧게 정의해주는 것 입니다.
for doc in data:
noPunctionWords = re.sub(r"[^a-zA-Z]+", " ", str(doc)) #불용어처리(기호)
tokenizedwords = word_tokenize(noPunctionWords.lower()) #소문자처리 후 토큰화
stoppedwords = [w for w in tokenizedwords if w not in stopWords] #불용어처리(단어)
stemmedwords = [stemmer.stem(w) for w in stoppedwords] #어간추출
words_joined.append(' '.join(stemmedwords)) #단어를 문장으로 합쳐줌
words.append(stemmedwords) #단어 그대로 저장한다.
11장에서 불용어 처리 방법 3가지 중 첫번째 방법을 사용해 전처리를 합니다.
< 참고 : 11.단어 및 불용어 2차정제 >
-
불용어처리
re 패키지의 sub()함수를 사용해서 불용어인 기호와 숫자를 처리하였습니다.
re.sub(r”[^a-zA-Z]+”,” “,str(doc)) 구문을 살펴보자면 a-zA-Z는 모든 알파벳을 의미하고, 여기에 ^를 추가한 건 not과 같이 아니라는 의미입니다.
이를 []로 묶고 +를 붙여 ‘ ‘ 전체로 묶은 후에 r을 붙여주는 이유는 r이 문자 그대로 판단하라는 의미로 \ 를 ‘\’ 문자로 인식하라는 의미입니다.
즉, doc를 문자열(str)로 바꾼 후 모든 알파벳을 제외하고 “ “(공백)으로 바꾸라는 의미인 것입니다. -
토큰화
알파벳만 추출된 단어를 noPunctionWords에 할당하고 이를 소문자처리(.lower())한 후에 토큰화 시키는 구문이 word_tokenize(noPunctionWords.lower()) 입니다. -
불용어처리
토큰화된 단어가 tokenizedwords 되어 불용어처리를 위해 [w for w in tokenizedwords if w not in stopWords] 구문을 거치는데 이는 변수(tokenizedwords)의 단어(w)가 불용어(stopWords)가 아니라면(not in) stoppedwords에 반환해준다는 의미 입니다. -
어간추출
이렇게 불용어를 거친 stoppedwords의 단어가 하나씩 어간추출화(stemmer.stem(w)) 된 후에 stemmedwords 변수에 할당되어지고 이를 공복(“ “)으로 합쳐주는 함수 join을 통해 word 리스트로 저장(.append)해주게 됩니다.
11장과 다르게 추가된 부분이 마지막 words.append(stemmedwords) 구문이다. words는 토큰화된 단어를 그대로 리스트형태로 저장하는 반면 words_joined는 토큰화된 단어를 문장으로 만들어 저장된 형태이다.
| 변수명 | 형 |
|---|---|
| words | [‘comput’, ‘intellig’, ‘ci’, ‘involv’, ‘use’, ‘comput’, ‘algorithm’, ‘captur’, ‘hidden’, ‘knowledg’, ‘data’, ‘use’] |
| words_joined | [‘comput intellig ci involv use comput algorithm captur hidden knowledg data use’] |
이렇게 2가지 변수로 각 다른 형태로 저장하는 이유는 words_joined 형태로 저장된 데이터가 DTM 형태로 만들기 위한 countVectorizer.fit_transform() 명령문에 사용되어야하기 때문이다.
countVectorizer = CountVectorizer(max_features=50)
이 구문 또한 위와 같이 CountVectorizer 명령문을 countVectorizer에 사용하기 전 미리 정의해놓은 형태이다. max_features라는 것은 가장 사용이 많이된 단어 50개만 뽑는다는 의미이다.
이렇게 하는 이유는 단어는 2000개 정도 되는 단어를 모두 count해서 따로 저장해도 빈도가 높은 단어들이 유의미한 데이터를 가지기 때문에 내가 사용하고자 하는 단어의 갯수를 설정해 효율적으로 메모리를 사용하는 것이 좋다. 그렇다고 너무 적은 수의 단어를 할당하면 그 의미를 자세하게 살펴볼 수 없기 때문에 그 의미를 유의미하게 나타내면서 효율적인 수치를 입력하는 것이 좋다.
이번 실습에서는 쉽게 따라하기 위해 50개를 뽑지만 몇백개 정도를 뽑는 것이 유의미한 텍스트 분석을 할 수 있다.
dtm = countVectorizer.fit_transform(words_joined)
dtm_dense = dtm.todense()
print(dtm_dense)
dtm을 바로 분석에 사용할 수 있는 형태로 만들어주기 위해서 dtm.todense()를 사용해서 matrix구조로 변환해주었습니다.
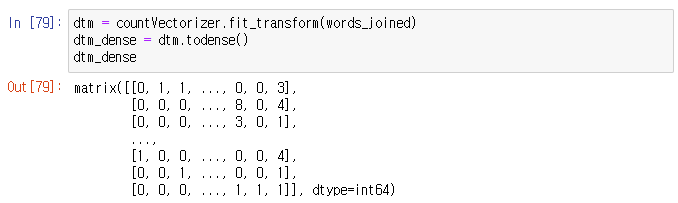
자료 형태를 보면 열이름(단어이름)이 저장되지 않기 때문에 따로 words_joined 데이터에서 열이름(단어이름)을 뽑아와 저장해줍니다.
dtm_name = countVectorizer.get_feature_names_out(words_joined)
dtm_name
버전 업데이트로 .get_featrue_names()에서 .get_featrue_names_out()으로 명령문이 바뀌었다. .get_featrue_names()사용시 에러(‘CountVectorizer’ object has no attribute ‘get_feature_names’)발생
상관관계분석
word_corr = np.corrcoef(dtm_dense,rowvar=True)
word_corr
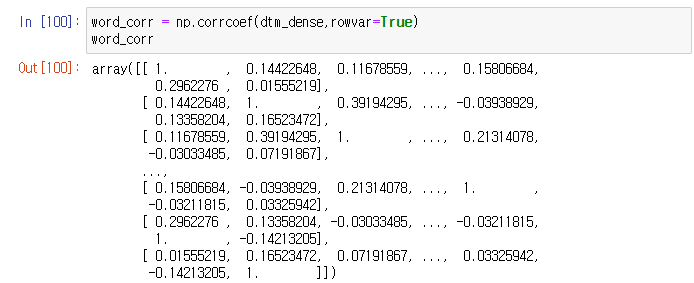
numpy의 corrcoef()로 단어간의 상관계수를 구해준다. 우리가 구한 상관계수는 단어 간의 상관계수로 ‘단어1이 쓰일때 단어2가 얼마나 쓰이는가’하는 상관관계를 나타낸다.
-
rowvar 부울, 선택 사항
rowvar 가 True(기본값) 이면 각 행은 변수를 나타내며 열에는 관측값이 있습니다. 그렇지 않으면 관계가 전치됩니다. 각 열은 변수를 나타내고 행에는 관측치가 포함됩니다.
-
자료가 dtm 형태로 행 = 문서, 열 = 단어로 우리가 구하기 위한 상관계수는 단어간의 상관계수 즉, 열의 상관계수이기 때문에 rowver에 True를 입력해 열 끼리의 상관계수를 구해준다.
D= pd.DataFrame(word_corr)
D
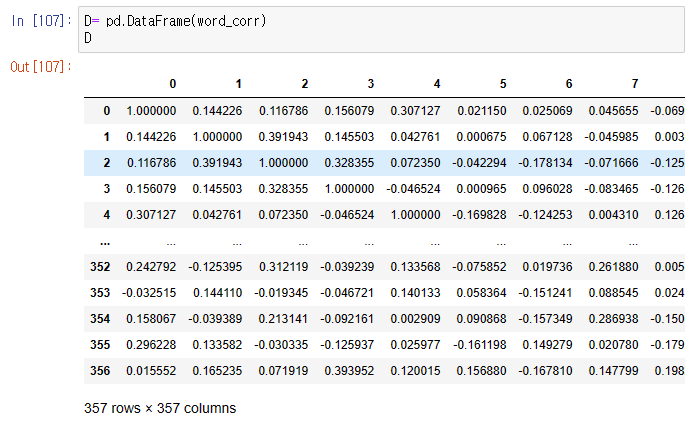
우리가 구한 상관계수를 데이터프레임(DataFrame) 형태로 살펴보면 아까보다 보기 쉽지만 열이름이 단어이름으로 부여되지 않아서 어떤 단어가 상관계수가 높은지 한눈에 알아보기가 힘들다.
해서 새로운 변수 word_edge에 열이름과 상관계수를 맞춰주는 작업을 통해 하나의 데이터프레임으로 만들어준다.
for i in range(dtm_dense.shape[1]):
for j in range (dtm_dense.shape[1]):
word_edges.append((dtm_name[i], dtm_name[j], word_corr[i,j]))
word_edges_sorted = sorted(word_edges, key=lambda x:x[2], reverse=True) #상관계수별로 정렬한다.
dtm_dense.shape는 DF의 (행의 수, 열의 수)를 반환해주는 것으로 dtm_dense.shape[1]은 열의 수를 반환해준다. 열의 수만큼 반복문을 실행해서 새로 만들어준 word_edges에 [ 단어1, 단어2, 단어1과 2의 상관계수 ] 를 하나의 튜플 형태로 저장한다.
저장된 word_edge는 리스트형태이다. 이를 람다문을 통해서 word_edge 원소를 하나씩 x에 대입해 x[2] = 상관계수를 기준(key) 로 정렬한다.
A=pd.DataFrame(word_edges_sorted)
A
이제 살펴보기 편하도록 DF형태로 만들어 확인해보자.
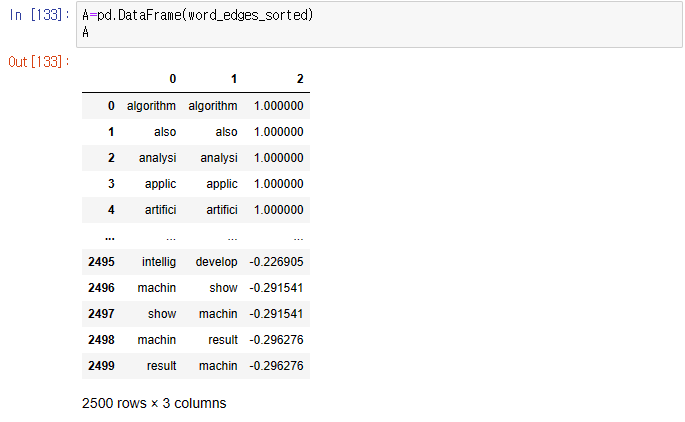
먼저 자신과의 상관계수가 1이므로 먼저 나오고, 상관계수가 높은 형태로 정렬된 것을 확인할 수 있다.
2. Word Network(네트워크분석)
2.1 TTM(DTM X TDM)
10강에서 DTM자료와 TDM자료를 살펴보았었다.
-
dtm = Document Term Matrix(문서 용어 행렬) 문서가 행에 오고 용어(단어)가 변수(열)에 오는 형태.
일반적으로 dtm자료로 분석을 많이한다. LDA, D-clustering, 단어빈도-cloud, 상관분석 등 -
tdm = Term Document Matrix(용어 문서 행렬) 문서가 열에오고 용어(단어)가 행에 오는 형태.
TDM은 Word-clustering 을 작업할때 쓰인다. - TTM : dtm x tdm 연산으로 Network를 만들때 쓰이는 자료구조이다.
TTM형태는 단어가 2000개라면 행렬이 2000x2000으로 엄청난 메모리를 잡아 먹기 때문에 edge list로 변환해서 사용한다. - edge list : 단어와 단어간의 Frequency(얼마나 연결되었는지)를 정리한 자료이다. TTM자료 형태보다 크기가 작아 TTM자료를 통해 분석하고자 할때 edge list 형태를 많이 사용한다.
위 실습을 통해서 TDM 자료를 가지고 상관계수를 구해 상관분석을 해보았다. 이번엔 TTM자료를 만들어 네트워크 분석을 통해 각 단어 간의 관계를 시각화해보자.
네트워크분석
import networkx as nx #네트워크 분석
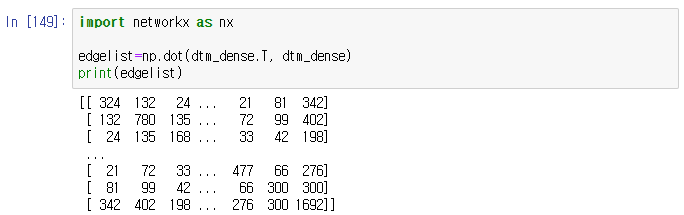
edgelist=np.dot(dtm_dense.T, dtm_dense)
print(edgelist)
networkx 패키지는 네트워크 분석을 위한 패키지로 네트워크 그림을 만들어주기 위해 import 해주었다.
TTM 자료를 만들기 위해서 먼저 TDM자료를 만들어주어야 하는데, TDM은 DTM자료의 행과 열이 바뀐 DTM의 전치행렬 형태이기 때문에 위에서 만든 dtm_dense인 dtm자료에 전치행렬(dtm_dense.T) 해서 TDM자료를 만들었다.
np.dot(x,y)은 행렬연산 명령어로 DTM과 TDM을 연산해 TTM자료로 만들어 edgelist 변수에 할당해줌.
ngraph = nx.Graph(edgelist[:, :])
ngraph_map = dict(zip(ngraph.nodes(), dtm_name))
nx.Graph는 네트워크 그림을 그리기 위한 명령문으로 ngraph에 할당해둔다.
네트워크 분석에서 한 노드가 다른 노드와의 연결성을 확인할 수 있는데 우리는 단어 간의 연관성을 보기 위함이므로 ngraph.nodes()는 단어를 의미한다. zip 명령문을 통해 각 노드(단어)에 dtm_name 단어이름을 묶어준다.
ngraph_map의 형태를 살펴보면 아래와 같다.

ngraph_map이 네트워크 분석 전에 필요한 edge list 형태를 갖추고 있음을 알 수 있다.
nx.draw_networkx(ngraph, labels=ngraph_map, with_labels=True)
plt.show()
nx.draw_networkx 명령문을 통해서 네트워크 그림을 그려보자.
with_labels = True로 할당해 각 노드의 이름(단어이름)을 확인할 수 있도록 한다.

이렇게 네트워크 분석을 그려볼 수 있다.
댓글남기기