20.LDA 결과의 시각
20강 LDA 분석과 결과의 해석
01. 패키지와 데이터 불러오기
!pip install pyLDAvis
import pyLDAvis.gensim
import gensim
from gensim import corpora
# from sklearn.externals import joblib
import joblib
import sklearn
sklearn.externals.joblib = joblib
시각화하기 위해서 pyLDAvis 패키지를 설치하고 19강에서 불러왔던 패키지를 그대로 import 해준다.
en_dict = gensim.corpora.Dictionary.load_from_text('en_lda_dict.txt')
en_corpus = gensim.corpora.MmCorpus('en_lda_corpus.mm')
en_lda = joblib.load('en_lda_model.pkl')
19강에서 저장해줬던 3개의 파일을 그대로 불러옵니다.
단어를 저장해둔 en_dict, bow인 en_corpus, lda모델인 en_lda를 각각 불러와서 저장해줍니다.
en_lda_ldavis = pyLDAvis.gensim.prepare(en_lda, en_corpus, en_dict)
pyLDAvis.save_html(en_lda_ldavis, 'en_lda_ldavis.html')
pyLDAvis 패키지를 사용해서 lda 시각화 모형을 따로 html에서 확인하기 위해서 html로 저장해줍니다
2. 시각화 해보기
저장되어 있는 en_lda_ldavis.html 파일을 크롬을 통해서 열어서 확인해보자
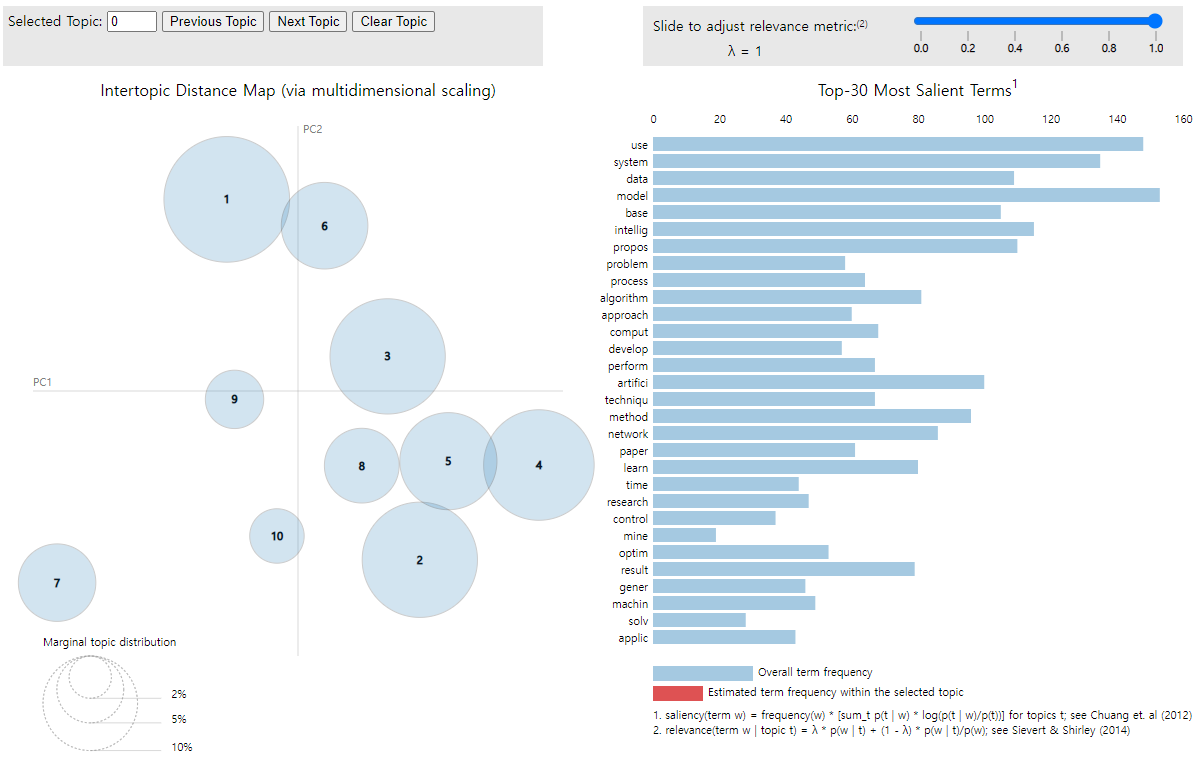
10개의 군집으로 되어 있는 topic들을 확인할 수 있다.
각 군집을 클릭하면 해당 군집에 대한 단어와 차지하는 비율을 확인해볼 수 있다.
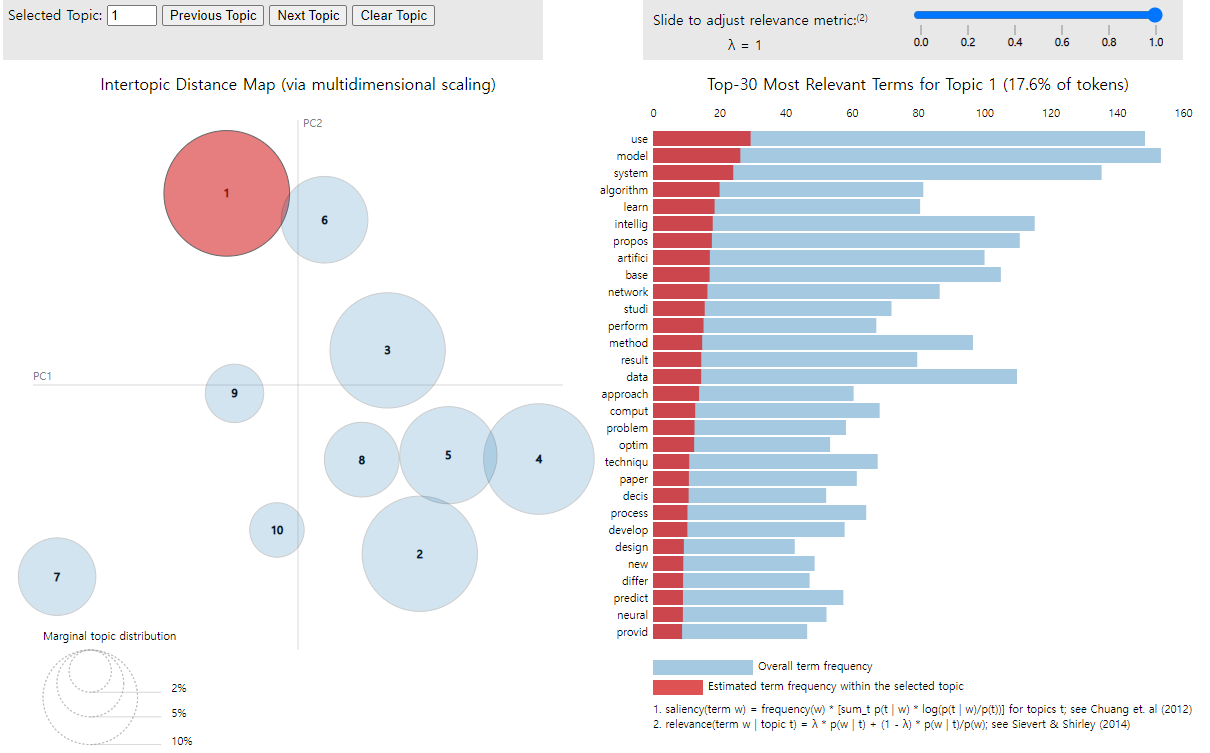
첫번째 군집같은 경우는 17.6%를 가진 가장 큰 군집으로 가장 많은 단어를 품고 있고 10번째 토픽이 가장 작은 군집인 것을 한눈에 확인할 수 있다.
클릭하면 위와 같이 어떤 단어들이 어느정도 포함되어 있는지 확인할 수 있다.
여기서 주의해야할 점은 19강에서 확인했던 군집의 순서가 아니기 때문에 안에 있는 단어로 확인해볼 필요가 있다.
모든 군집에서 자주 출현하는 단어를 정제할 필요가 있어보인다.
댓글남기기