19.LDA 분석과 결과의 해석
19강 LDA 분석과 결과의 해석
01. 패키지와 데이터 불러오기
import pandas as pd
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
import re
import gensim
from gensim import corpora
# from sklearn.externals import joblib
import joblib
import sklearn
sklearn.externals.joblib = joblib
16,17강에서 불러왔던 동일한 패키지를 불러오고,
여기서 gensim 패키지에서 corpora를 불러오는데 이는 분석 시에 이전과 같은 word형태로 묶은 것이 아닌 corpus 단위로 저장하기 위해서 사용한다.
en_data=pd.read_csv('wos_ai_.csv', encoding='euc-kr')
en_data_abstract = en_data['ABSTRACT']
실습파일을 불러온다. 여기서 ‘ABSTRACT’열에 해당되는 부분만 en_data_abstract 변수에 저장해준다.
02. 전처리 및 corpus 준비
en_doc = [] #문서집
en_word_joined = [] #문장집
en_word = [] #단어집
전처리를 위한 문서집, 문장집, 단어집에 해당되는 변수를 각각 만들어준다
for doc in en_data_abstract:
if type(doc) != float: #숫자가 아닌 문서에 해당되는 부분만
en_doc.append(doc.replace("-", " ")) #"-"을 공백으로 바꿔 저장
en_stopwords = set(stopwords.words("english")) #불용어 사전 저장
en_stemmer = PorterStemmer() #어간추출을 위한 명령어 저장
#전처리 과정
for doc in en_doc:
en_alphabet = re.sub(r"[^a-zA-Z]+", " ", str(doc)) #알파벳만 추출
en_tokenized = word_tokenize(en_alphabet.lower()) #소문자화, 토큰화
en_stopped = [w for w in en_tokenized if w not in en_stopwords] #불용어처리
en_stemmed = [en_stemmer.stem(w) for w in en_stopped] #어간추출
en_word_joined.append(' '.join(en_stemmed)) #join해서 문장별로 저장
en_word.append(en_stemmed) #join하지 않고 전처리된 단어를 저장
dtm, tdm자료를 만들때는 TfidfVectorizer() 명령문을 사용해서 백터라이즈 하기 위해 전처리한 자료를 join하였다.
LDA에서는 join하지 않은 형태로 사용하기 때문에 따로 join하지 않았다.
저장한 en_word_joined와 join하지 않은 en_word를 확인해보자.
en_dict = corpora.Dictionary(en_word)
en_corpus = [en_dict.doc2bow(word) for word in en_word]
en_corpus
en_word를 Dictionary 형태로 만들기 위해서 corpora 패키지의 Dictionary명령어를 사용한다.
그리고 BOW(Back of word 단어가방)형태로 만들기 위해서 반복문 구문으 사용한다. 이렇게 만들어진 en_corpus는 (몇번째단어, 단어의빈도)형태로 저장된다.
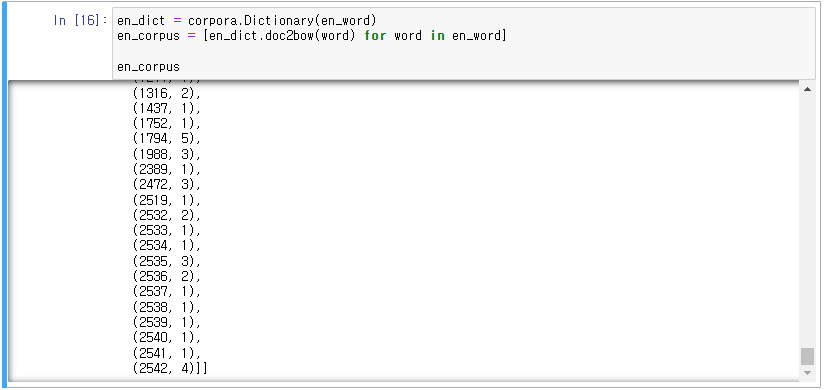
이렇게 en_corpus를 확인해보면 2542개의 단어의 빈도가 순서대로 저장되어 있는 것을 확인할 수 있다. 2542번째의 단어가 4번 출현한 것을 확인할 수 있다.
03. LDA 모델링
en_lda = lda_ = gensim.models.ldamulticore.LdaMulticore(en_corpus,iterations=12, num_topics=10,id2word=en_dict, passes=1, workers=10)
gensim 패키지의 models 중에 LDA 명령어를 사용한다
만들어진 BOW인 en_corpus 변수를 사용한다. 여기서 중요한 부분은 num_topics 로 주제를 몇개로 하겠냐는 것이다.
num_topics의 수를 조정해가면서 가장 괜찮은 주제의 수를 선정해주는 것이 좋다.
id2word에서 en_dict를 설정해주는 이유는 기준이 되는 단어인 en_dict를 설정해줘야 출력시에 어떤 단어인지 확인이 된다.

LDA 구조를 먼저 확인해보자. 총 2543개이며 주제는 10개인 것을 확인할 수 있다.
이제 LDA를 통한 결과물을 확인해보자.

LDA의 10개 주제로 나누어진 단어들을 확인해볼 수 있다.
num_words는 해당 주제에서 몇개의 단어만 출력해내겠냐는 설정값이다.
여기서 단어 앞에 계수는 단어가 해당 topic에 등장할 확률이다.
lda = en_lda.print_topics(num_topics=30, num_words=30)
lda_df_all = []
for i in range(0,10) :
lda_df_a=[]
col = lda[i][1].split("+")
lda_df = []
for j in col :
lda_df.append(j)
lda_df_a.append(i)
lda_df_a.append(lda_df)
lda_df_all.append(lda_df_a)
pd.DataFrame.from_dict(dict(lda_df_all))
결과물을 lda로 저장하여서 데이터프레임 형태로 알아보기 쉽게 형태를 바꿔보자.
topic을 열, 단어를 행으로 두고 “+”를 기준으로 잘라준 후에 이를 list형태로 저장한 후에 데이터프레임 형태로 바꿔주었다.

- 0번째 주제의 단어를 보면 [ai, develop, techniqu, power] 등 산업에 관련되어 있고,
- 1번째 주제의 단어를 보면 [algoithm, prefrom, reserch, featur ] 등을 보면 방법론에 대한 주제일 것 같고,
- 2번째 주제의 단어를 보면 [dics, time, nerural] 등을 보면 신경망에 관련된 주제일 것이라 보인다.
- 대부분 20번째까지의 단어들은 모든 topic에서 자주 쓰이기 때문에 단어들을 30개가 아니라 50개 정도 더 많이 확인을 해서 주제의 특성을 잡는 것이 좋다.
04. 시각화를 위한 파일 저장
다음 챕터의 시각화를 위해 파일을 저장해보자.
en_dict.save_as_text('en_lda_dict.txt')
위에서 만들었던 dictionary로 단어를 저장한 en_dict를 텍스트 파일로 저장해주고
corpora.MmCorpus.serialize('en_lda_corpus.mm', en_corpus)
bow형태로 저장한 en_corpus 변수는 corpora에서 제공하는 명령어를 통해 저장해준다.
joblib.dump(en_lda, 'en_lda_model.pkl')
마지막으로 lda모델을 저장해주면 다음 챕터를 위한 준비작업은 끝이난다.
댓글남기기