17.Document Clustering 실습
17강 Document Clustering 실습
01. 패키지와 데이터 불러오기
import pandas as pd #데이터처리
from nltk.tokenize import word_tokenize #토큰화
from nltk.corpus import stopwords #불용어
from nltk.stem import PorterStemmer #어간추출
import re #정규표현식
import sklearn #특징추출의 문서
from sklearn.feature_extraction.text import TfidfVectorizer #TF-IDF
from sklearn.cluster import KMeans #군집분석
from scipy.cluster.hierarchy import dendrogram, linkage, ward
from sklearn.metrics.pairwise import cosine_similarity #거리 표준화
import matplotlib.pyplot as plt #plot 그리기
en_data=pd.read_csv('wos_ai_.csv', encoding='euc-kr')
en_data_abstract = en_data['ABSTRACT']
16강 Word Clustering 실습에서 불러왔던 패키지와 데이터를 동일하게 불러왔다.
02.데이터 전처
en_doc = [] #문서집
en_word_joined = [] #문장집
en_word = [] #단어집
분석을 위한 문서집, 문장집, 단어집에 해당하는 변수를 만든다.
for doc in en_data_abstract:
if type(doc) != float:
en_doc.append(doc.replace("-", " "))
문서를 반복문을 통해서 문자만(!= float 숫자가 아닌 것) en_doc 변수에 넣어주는데 이때 하이픈 “-“ 은 공백 “ “으로 처리해서 넣는다.
en_stopwords = set(stopwords.words("english"))
en_stemmer = PorterStemmer()
불용어 사전을 en_stopwords 변수에 넣어주고
어간추출을 위한 명령어를 en_stemmer 변수에 넣어준다.
for doc in en_doc:
en_alphabet = re.sub(r"[^a-zA-Z]+", " ", str(doc))
en_tokenized = word_tokenize(en_alphabet.lower())
en_stopped = [w for w in en_tokenized if w not in en_stopwords]
en_stemmed = [en_stemmer.stem(w) for w in en_stopped]
en_word_joined.append(' '.join(en_stemmed))
en_word.append(en_stemmed)
위에 대한 전처리 과정에 대한 설명은 아래 링크를 통해서 확인 할 수 있다.
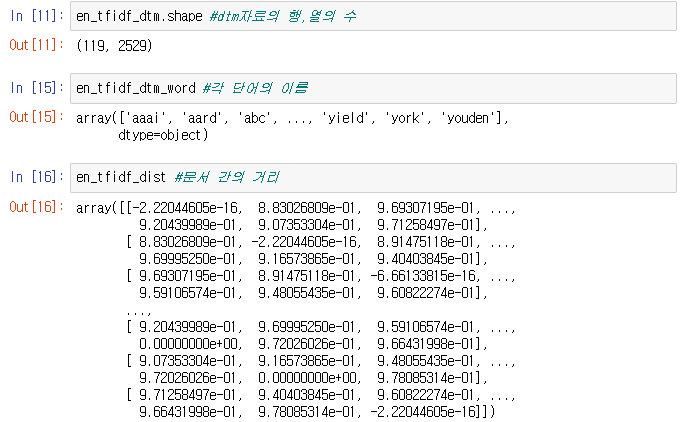
03. 문서간 거리계산
en_tfidf_vectorizer = TfidfVectorizer()
en_tfidf_dtm = en_tfidf_vectorizer.fit_transform(en_word_joined)
en_tfidf_dtm_word = en_tfidf_vectorizer.get_feature_names_out()
en_tfidf_dist = 1-cosine_similarity(en_tfidf_dtm)
-
TF-IDF로 계산해주는 명령어 TfidfVectorizer를 en-tfidf-vectorizer 변수에 넣어준다.
- 이제 en_tfidf_dtm에 분석을 위한 DTM 자료를 넣어준다. DTM자료로 만들어주는 fit_transform 명령어를 사용하고, 각 단어들의 이름을 따로 en_tfidf_dtm_word 변수에 넣어주자. 이때 DTM자료로 저장하는 이유는 문서간의 군집분석을 위한 것이기 때문에 문서를 행, 단어를 열로 저장하는 DTM자료가 필요하다.
- en_tfidf_dist에는 consine 표준화를 시켜주는 consine_similarity를 통해서 단어의 유사성에 대한 값을 구해주는데, 이때 이 값을 1로 빼줌으로써 거리 값으로 저장해준다. 왜냐하면, consine_similarity로 구한 값은 유사성이 높으면 높은 값을 가지게 되는데, 우리는 거리 값으로 유사성이 높으면 거리가 짧아야하기 때문에 1을 빼줌으로써 거리 값으로 저장해주는 것이다.
각 만들어진 변수들을 살펴보면 아래와 같다.
04. 군집분석 수행
k=5
en_kmeans_model=KMeans(n_clusters=k, init='k-means++', max_iter=100, n_init=10, random_state=777).fit(en_tfidf_dtm)
단어간의 군집분석 때 사용된 옵션 값과 같이 지정해주자.
- 군집 수를 5로 지정해준 후 K클러스터링 방법을 사용해보자.
- n_clusters 클러스터 수
- init = k-means 방법으로 군집화 한다.
- max_iter 최대 반복수는 100으로 한다.
- n_init 수렴도는 10
- random_state는 군집분석을 할때마다 중심점을 어디로 잡느냐로 다른데 이 숫자를 변경시켜가면서 똑같은 결과가 나오는지 확인해볼 수 있다.
order_centroids=en_kmeans_model.cluster_centers_.argsort()[:, ::-1]
이제 군집별로 문서 간의 어떤 단어로 이루어지는지 확인해보기 위해 위와 같은 명령어를 order_centroids에 저장해둔다.
- .argsort()[:, ::-1] 는 군집을 정렬해서 확인하기 위한 구문이다.
en_kmeans_model_doc_label = en_kmeans_model.labels_
각 문서에 해당하는 군집의 인덱스를 en_kmeans_model_doc_label에 따로 저장해주자.
for i in range(k):
label_cluster= np.where(en_kmeans_model_doc_label==i)[0].tolist()
word_cluster = []
for ind in order_centroids[i, :30]:
word_cluster.append(en_tfidf_dtm_word[ind])
print('* Cluster {}'.format(i))
print('Document Numbers: {}'.format(' '.join(str(x) for x in label_cluster)))
print('Words: {}\n'.format(' '.join(str(x) for x in word_cluster)))
- i 는 군집을 표현하는 것으로 1번 군집이면 “* Cluster 1”로 추출된다.
- 우리가 저장한 en_kmeans_model_doc_label을 통해서 1번 군집에 해당되면 np.where 절을 통해서 1번 군집에 해당되는 문서의 인덱스를 추출한다.
- 군집에 해당되는 문서가 어떤 단어를 가졌는지 확인하기 위해 만들어 두었던 order_controids를 통해서 군집에서 30개의 단어를 추출한다.
- 각 군집의 번호, 군집의 문서번호, 군집의 단어를 print 하여 확인해본다.
추출된 결과는 아래와 같다.

05. 덴드로그램 시각화
en_linkage_matrix=ward(en_tfidf_dist)
fig, ax=plt.subplots(figsize=(25,15))
plt.title('Clustering Dendrogram')
plt.ylabel('Distance')
plt.xlabel('Documents')
ax=dendrogram(en_linkage_matrix, leaf_font_size=10, leaf_rotation=50, orientation='top')
plt.show()
단어 군집화시 덴드로그램 옵션 값과 동일하게 주어 결과물을 확인해보자.
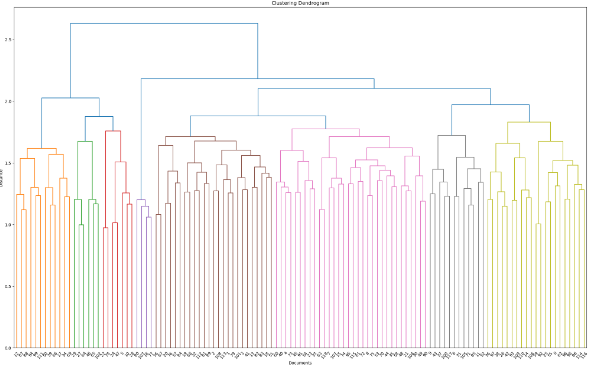
위와 같이 문서간의 군집분석을 덴드로그램으로 시각화 해보았다.
댓글남기기