16.Word Clustering 실습
💡목표
- 단어 군집분석을 해보자
- Kmeans 군집법을 통해 단어 군집화 하기
- 덴드로그램으로 표현해보기
16강 Word Clustering 실습
01. 패키지와 데이터 불러오기
import pandas as pd #데이터처리
from nltk.tokenize import word_tokenize #토큰화
from nltk.corpus import stopwords #불용어
from nltk.stem import PorterStemmer #어간추출
import re #정규표현식
import sklearn #특징추출의 문서
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans #군집분석
from scipy.cluster.hierarchy import dendrogram, linkage, ward
import matplotlib.pyplot as plt #plot 그리기
전처리를 위한 패키지들과 이번 문서의 특징 추출을 위해 TfidVectorzier 라이브러리와 군집분석에서 그림을 그리기 위한 dendrogram, 군집 간의 거리 조절을 위한 linkage, 군집법을 위한 ward를 불러온다.
02. 데이터전처리
data=pd.read_csv('wos_ai_.csv', encoding='utf-8').ABSTRACT
doc_set=[] #문서집
words=[] #단어집
실습때 사용해왔던 ‘wos_ai_.csv’ 파일의 ‘ABSTRACT’ 열을 불러오고 문서집과 단어집으로 사용할 공간을 만들어준다.
stopWords=set(stopwords.words("english"))
stemmer=PorterStemmer()
사용할 불용어 사전을 stopWords에 넣어주고, 어간추출을 위한 명령어를 stemmer에 저장한다.
for doc in data:
if type(doc)!=float:
doc_set.append(doc.replace("_", " "))
data는 데이터프레임 형식으로 저장되어 있는데 이때 하나의 열에 대한 데이터가 문서라면(숫자가 아니라면 ‘!=float’) doc_set에 넣게 되는데 이때 언더바 “_“를 공백 “ “으로 바꿔준다.
이때 doc_set은 리스트로 저장된다.
# 전처리 과정
for doc in doc_set:
noPunctionWords = re.sub(r"[^a-zA-Z]+", " ", str(doc)) #알파벳을 제외하고 공백처리
tokenizedwords = word_tokenize(noPunctionWords.lower()) #토큰화
stoppedwords = [w for w in tokenizedwords if w not in stopWords] #불용어처리
stemmedwords = [stemmer.stem(w) for w in stoppedwords] #어간추출
words.append(" ".join(stemmedwords)) #전처리된 단어를 문장으로 다시 이어준다.
위에 대한 전처리 과정에 대한 설명은 아래 링크를 통해서 확인 할 수 있다.
전처리 된 텍스트를 확인해보면 아래 사진과 같다.
03. 단어간 거리 계산
vectorizer=TfidfVectorizer(stop_words='english')
위에 패키지를 불러오는 과정에서 불러왔던 TfidfVactorizer를 사용하기 위해 해당 명령어를 vectorizer에 저장해서 사용하기 변수에 편하게 지정해준다.
TfidfVactorizer는 거리 계산 시에 TF-IDF 값을 계산해주는데, 단어의 빈도가 한 쪽으로 쏠리지 않도록 조정해준다. TF-IDF의 대한 상세설명은 아래의 링크를 참고하자.
TfidfVectorizer에서도 제공해주는 stop_words 불용어 사전을 사용해서 한번더 불용어 처리를 해주겠기 위해서 옵션을 지정해주었다. 여기서 옵션을 정해준 것은 나중에 사용하기 위해 편하게 변수로 지정해둔 것이다.
X=vectorizer.fit_transform(words)
X.shape
vectorizer를 사용해서 분석에 사용하기 위한 형태 DTM자료로 만든다. 여기서 shape를 통해서 행,열의 갯수를 살펴보면 (119, 2435)로 행에 문서가 119개가 있고 열에는 단어가 2435개 임을 확인할 수 있다.
이러한 DTM자료로 군집분석을 할 경우에 문서 간의 군집분석을 하게 되는데 우리는 단어간의 군집분석을 할 것이기 때문에 TDM자료로 만들어줘야한다.
해서 df.T 명령어를 통해서 전치행렬로 만들어 행열 전환을 해줌으로써 TDM자료로 만들어주자.
X=vectorizer.fit_transform(words).T
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.externals import joblib
dist=1-cosine_similarity(X)
이제 유사성을 계산하기 위해 cosine_similarity 명령어를 사용하자. 단어의 거리를 표준화하는 방법은 크게 Z값, cosine, min-max 있는데 우리는 단어분석에서 많이 쓰이는 cosine으로 표준화 하였다.
이때 유의해야할 점은 cosine_simailarity는 유사성을 계산해주는 것으로 유사성이 클수록 숫자가 크다. 그러나, 우리는 군집분석 시에 거리가 가까우면 유사성이 크고 거리가 멀면 유사성이 작다는 점을 활용하기에 여기서 1을 빼주어 거리의 값으로 만든다.
여기서 import 과정에서 cannot import name ‘joblib’ from ‘sklearn.externals’ 오류가 생길 시에 아래의 코드를 실행 한 후에 ‘consine_similarity’ 명령어를 사용해보자.
!pip install scikit-learn --upgrade
import joblib
import sklearn
sklearn.externals.joblib = joblib
[출처) Cannot import name 'joblib' from 'sklearn.externals' [Fixed]]
04. K-means 군집방법 수행
k=5
model=KMeans(n_clusters=k, init='k-means++', max_iter=100, n_init=10, random_state=777).fit(X)
- 군집 수를 5로 지정해준 후 K클러스터링 방법을 사용해보자.
- n_clusters 클러스터 수
- init = k-means 방법으로 군집화 한다.
- max_iter 최대 반복수는 100으로 한다.
- n_init 수렴도는 10
- random_state는 군집분석을 할때마다 중심점을 어디로 잡느냐로 다른데 이 숫자를 변경시켜가면서 똑같은 결과가 나오는지 확인해본다.
order_centroids=model.cluster_centers_.argsort()[:, ::-1]
이제 군집별로 어떤 단어를 중심으로 이루는지 확인해보기 위해 위와 같은 명령어를 order_centroids에 저장해둔다.
- .argsort()[:, ::-1] 는 군집을 정렬해서 확인하기 위한 구문이다.
terms=vectorizer.get_feature_names_out()
terms
이제 군집별 단어를 확인하기 위해 먼저 verctorizer에 저장해둔 각 단어들을 terms에 저장시킨다.
for i in range(k):
print("Cluster %d" % i),
for ind in order_centroids[i, :50]:
print(' %s' % terms[ind], end='\t')
print('\t')
- i 는 군집을 표현하는 것으로 1번 군집이면 “Cluster 1”로 추출된다.
- 군집별로 50개의 단어를 저장해둔 order_centroids를 통해 해당되는 군집의 단어가 정렬되어 추출된다. 다 보여주면 ‘\t’ 엔터.
추출된 결과는 아래와 같다.
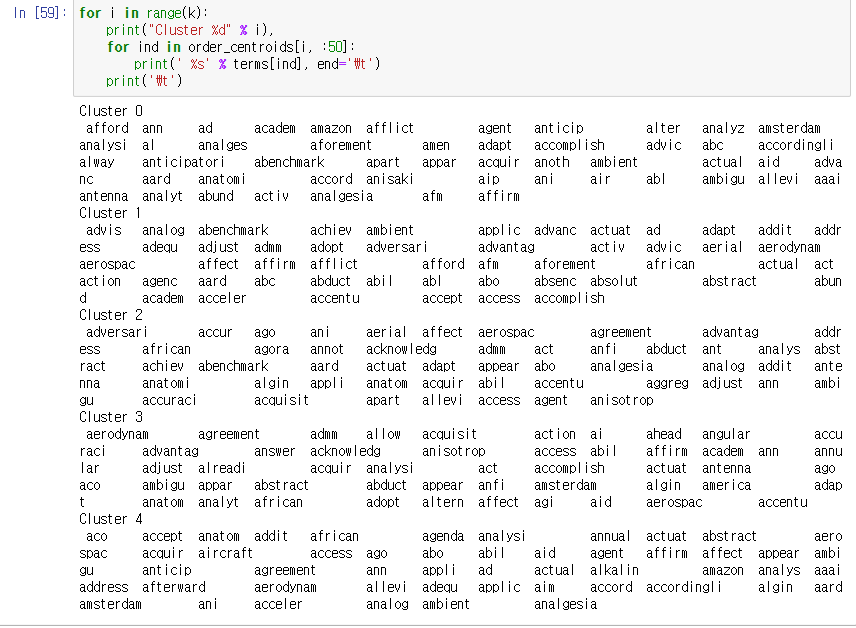
이제 결과 값을 살펴보고 덴드로그램으로 나타내보자.
05. 덴드로그램 시각화
linkage_matrix=ward(dist)
덴드로그램을 작성하기 위해서 거리를 ward로 작성한다.
fig, ax=plt.subplots(figsize=(25,15)) #크기
plt.title('Clustering Dendrogram') #타이틀
plt.ylabel('Distance') #y제목
plt.xlabel('Word') #x제목
ax=dendrogram(linkage_matrix, leaf_font_size=10, leaf_rotation=50, orientation='top', labels=terms)
plt.show
해당 명령어를 통해서 덴드로그램을 만들어보자.
- ward로 작정한 거리를 linkage_matrix로 주고, 폰트사이즈(leaf_font_size)는 10, 각 라벨은 terms(단어의 이름)으로 표시
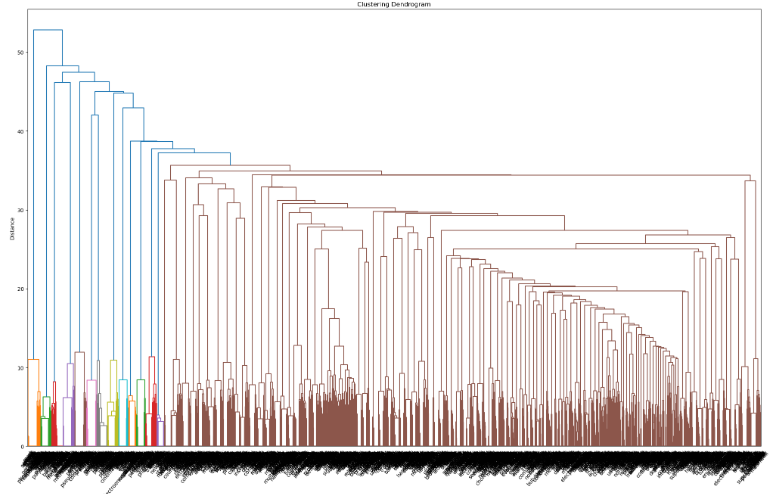
완성한 덴드로그램은 위와 같이 빽빽한 그래프임을 확인할 수 있다. 이는 아까 50개의 단어에서 수를 조정해가며 연구자가 단어를 파악해보아야 한다.
댓글남기기