14.Sentiment Analysis 실습
💡목표
- 감정분석을 위한 사전준비 하기
- 감정점수 계산하기
- 감정점수 시각화하기
14강. Sentiment Analysis 실습
01. 패키지 및 데이터파일 불러오기
import pandas as pd #데이터 구조
from nltk.tokenize import word_tokenize #토큰화
from nltk.corpus import stopwords #불용어
from nltk.stem import PorterStemmer #어간추출
import re #정규표현식
file=pd.read_csv('wos_ai_.csv', encoding='utf-8')
데이터 전처리에 필요한 패키지와 wos_at_.csv 데이터의 ABSTRACK 열만 추출해서 불러들입니다.
file=pd.DataFrame(file)
file.info()
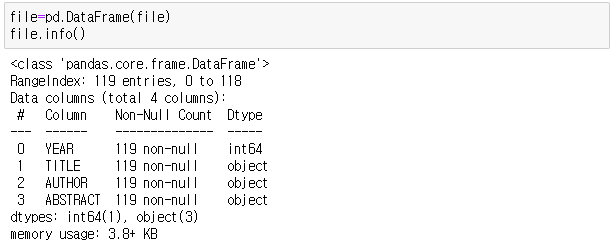
file의 데이터구조를 살펴보면, 년도(YEAR), 제목(TITLE), 작가(AUTHOR), 초록(ABSTRACT)를 확인할 수 있습니다.
여기서 저희는 ABSTRACT 데이터로 감정분석을 하게 될텐데, 연도별로도 파악해보도록 하겠습니다.
02. 초록/연도 구분 및 데이터셋 준비
data = file.ABSTRACT
year = file.YEAR
doc_set = [] #문장을 저장할 공간
words = [] #단어들을 저장할 공간
wordsForSentiment = [] #감정분석을 위한 공간
ABSTRACT에 대한 데이터를 data 변수에 넣어주고 YEAR에 대한 데이터를 year 변수에 각각 넣어 주었습니다.
전처리 과정 중에 필요한 공간을 doc_set 문장구조로 넣을 공간과 words 단어로 넣을 공간을 지정해 줍니다. 그리고 감정분석을 위해 별도 공간도 wordsForSentiment 로 만들어주겠습니다.
03. 데이터 전처리 (영어만 남기기)
11강에서 진행했던 데이터전처리 과정을 진행해줍니다.
# "_" 구분자를 공백으로 바꿔주기
for doc in data:
if type(doc)!=float:
doc_set.append(doc.replace("_", " "))
# 불용어처리를 위해 불용어사전을 stopWords에 저장
stopWords=set(stopwords.words("english"))
# 어간추출을 위한 명령문을 따로 저장해두기
stemmer=PorterStemmer()
# 전처리 과정
for doc in doc_set:
noPunctionWords = re.sub(r"[^a-zA-Z]+", " ", str(doc)) #알파벳을 제외하고 공백처리
tokenizedwords = word_tokenize(noPunctionWords.lower()) #토큰화
stoppedwords = [w for w in tokenizedwords if w not in stopWords] #불용어처리
stemmedwords = [stemmer.stem(w) for w in stoppedwords] #어간추출
words.append(" ".join(stemmedwords)) #전처리된 단어를 문장으로 다시 이어준다.
wordsForSentiment.append(stoppedwords) #이어진 문장을 하나의 문서로 만들어줌
wordsForSentiment
자세한 전처리 과정에 대한 설명은 링크를 통해 확인해주세요.
전처리가 끝난 wordsForSentiment의 변수의 형태는 아래 사진 형태와 같다.
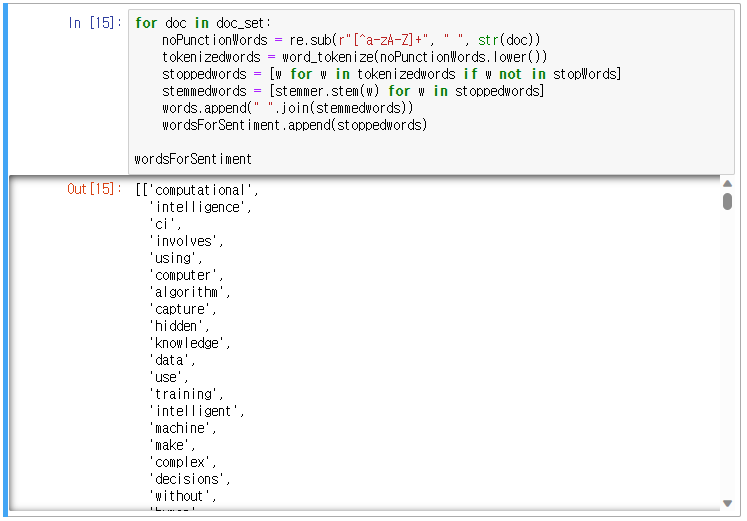
여기서 명심해야할 부분은 내가 가진 감정분석 사전이 전처리가 된 형태라면 위와 동일하게 진행하면 되지만 전처리가 되지 않은 형태의 사전이라면 어간을 추출하지 않은 stoppedwords의 변수를 사용해야 한다.
이는 연구자가 사용하는 감정분석 사전에 따라서 조정해야할 필요가 있다. 여기에선 전처리가 된 사전을 사용할 것이기에 위와 같은 전처리를 진행하였다.
이제 사전을 불러오자.
04. 감정사전으로 감정점수 계산하기
posFile=pd.read_csv("positive-words.txt", encoding='utf-8')
negFile=pd.read_csv("negative-words.txt", encoding='utf-8')
여기서 posFile의 데이터형태는 type(posFile) 명령문으로 살펴보면 데이터프레임 형태인데 우리가 만든 wordsForSentiment 변수의 데이터형태는 list 형태이기 때문에 같은 형태로 만들어 줘야한다.
- 참고: csv 파일을 여는 명령문으로 txt파일을 열고 있는데 csv로 txt 파일도 열려진다. 다만, xlsx(엑셀)파일은 read_excel() 명령문으로 열어야 한다.
posWords=set(posFile['POSITIVE'].tolist())
negWords=set(negFile['NEGATIVE'].tolist())
.tolist() 함수를 사용해서 데이터프레임형태에서 리스트형태로 바꿔준 후에 set에 넣어주자. 여기서 ‘POSTIVE’와 ‘NEGATIVE’로 지정해주는 이유는 아래 사진을 살펴보면
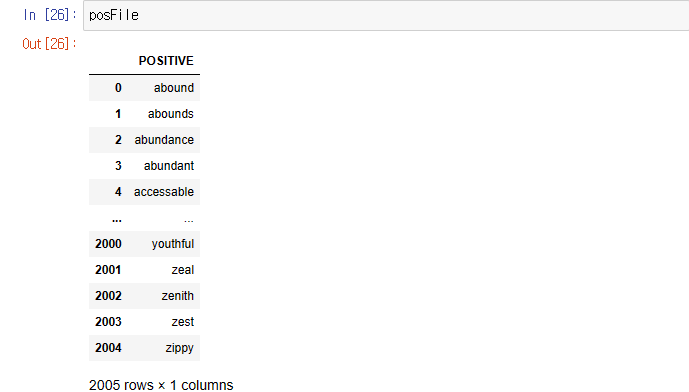
열 이름이 각자 ‘PSTIVE’와 ‘NEGATIVE’로 되어있기 때문에 해당 열의 데이터만 추출해서 리스트로 만들고 만들어진 리스트를 집합(set)에 넣어놓겠다는 뜻이다.
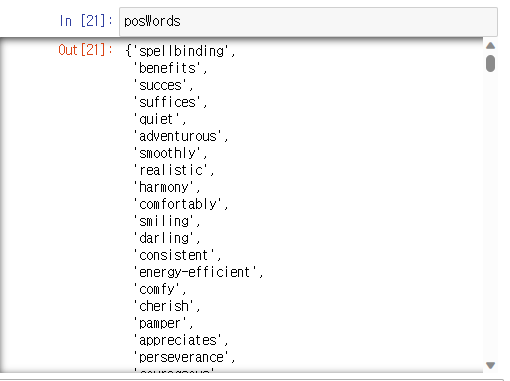
이렇게 set 형태로 담긴 것을 확인할 수 있다.
이제 감정분석을 위해서 긍정점수, 부정점수, 총점수를 저장할 공간을 만든다.
posScore=[] #긍정점수
negScore=[] #부정점수
sentScore=[] #총점수
for doc in wordsForSentiment:
posS=len([w for w in doc if w in posWords])
negS=len([w for w in doc if w in negWords])
sentS=posS-negS
posScore.append(posS)
negScore.append(negS)
sentScore.append(sentS)
아까 만들어진 전처리가 끝난 wordsForSentiment의 단어들을 반복문으로 점수를 넣어준다.
- wordsForSentiment의 단어를 doc에 넣어서 posWords 긍정단어에 속하는지 if문으로 확인하고 긍정단어에 속한 단어의 갯수(len())를 구해 posS 변수에 넣어주었다.
- 마찬가지로 negWords 부정단어에 속하는지 if문으로 확인해서 부정단어 갯수를 구해서 negS 변수에 넣어주었다.
- sentS 총 점수는 긍정점수(posS) - 부정점수(negScore)로 구하고 문장별로 긍정, 부정, 총 점수를 각 posScore, negScore, sentScore에 저장해주었음.
05. 연구별 감정점수 데이터프레임으로 정리
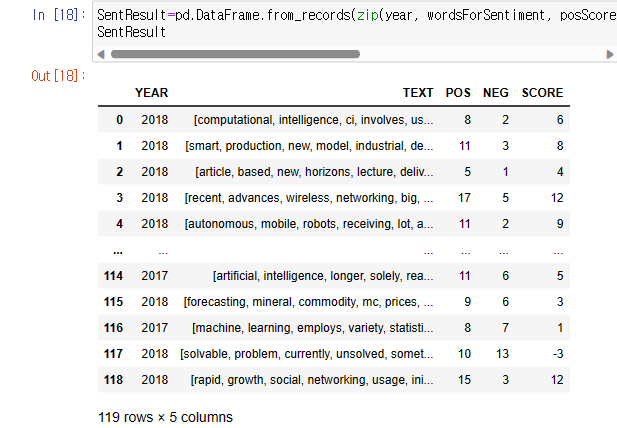
이제 텍스트의 연도, 텍스트, 긍정점수, 부정점수, 총점수를 하나의 데이터프레임으로 만들어보자.
SentResult=pd.DataFrame.from_records(zip(year, wordsForSentiment, posScore, negScore, sentScore), columns=['YEAR', 'TEXT', 'POS', 'NEG', 'SCORE'])
SentResult
- pd.DataFrame 은 데이터프레임으로 만들어주는 pandas에서 제공해주는 명령문으로 .from_recods는 행 순서대로 데이터를 배치한다. ex : data = [(1,2),(3,4),(5,6)] pd.DataFrame.frome_records(data, columns=[‘col1’,’col2’]) col1 col2 0 1 2 1 3 4 2 5 6
- zip은 열로 변수들을 묶어주는 명령어로 위에서 만들어준 변수들 연도(year), 전처리된 텍스트(wordsForSentiment), posScore(긍정점수), negScore(부정점수), sentScore(총점수)를 묶어주었음.
- column의 이름을 부여해주는 columns = [] 옵션으로 컬럼이름을 지정해주었음.
만들어진 SentResult 데이터프레임을 확인해보면 아래와 같다.
이제 연도별로 점수를 확인해보자.
sentSummary=SentResult.groupby('YEAR', as_index=False)['POS', 'NEG', 'SCORE'].mean()
sentSummary
- SentResult 데이터프레임을 groupby를 통해서 ‘YEAR’를 기준으로 ‘POS’, ‘NEG’, ‘SCORE’의 평균점수(.mean)를 확인해본다.
- as_index=False 는 인덱스를 주지 않겠다는 의미.
이에 대한 sentSurmmary를 살펴보면 아래와 같다.

여기선 ‘YEAR’로 groupby 했기 때문에 2017년도, 2018년도로 연도별로 확인할 수 있다. 이외에도 성별이나 출처별로 그룹해 나타낼 수도 있다.
06. 연도별 감정점수 시각화
import matplotlib.pyplot as plt #시각화를 위한 패키지
import numpy as np #점수산출을 위한 패키지
먼저 시각화를 위한 plot를 그리는 패키지와 점수산출을 위해 numpy 패키지를 불러온다.
그리고 막대그래프의 막대넓이와 라인그래프의 라인넓이를 정해주자.
barWidth=0.25
lineWidth=2
각 막대넓이는 0.25, 라인넓이는 2로 정해주고,
각 막대들의 높이를 정하기 위해서 먼저 df의 위치값을 저장해주자
graphPOS=np.arange(len(sentSummary.POS)) #POS 위치값
graphNEG=[x+barWidth for x in graphPOS] #NEG 위치값
graphSCORE=np.arange(len(sentSummary.SCORE)) #SCORE 위치값
- graphPOS 값은 POS 막대그래프의 위치이다. 이 위치에 대한 값을 정해주기 위해 먼저 sentSummary 형태를 살펴보자.
- 이 sentSummary 데이터프레임을 보면 각 POS, NEG, SCORE 모두 2개의 값을 가지고 있다. 이러한 값들의 위치를 정해주기 위해서 len과 arange 함수를 사용하였다.
- len()은 갯수를 반환해주는 명령문으로 len(sentSummary.POS)는 POS열의 데이터갯수가 2개이므로 2를 반환해준다.
- np.arange() 함수는 numpy 패키지의 함수로 arange(2)가 입력시 array([0,1]), arange(3)입력시 array([0,1,2])로 반환해주는 배열을 만들어주는 함수이다.
- 그렇다면 NEG 위치값은 왜 저렇게 정해준 것일까? 그건 아래의 그래프 결과물을 보며 설명하겠다.
plt.bar(graphPOS, sentSummary.POS, color='cyan', width=barWidth, edgecolor='white', label='POS')
plt.bar(graphNEG, sentSummary.NEG, color='magenta', width=barWidth, edgecolor='white', label='NEG')
plt.bar(graphSCORE, sentSummary.SCORE, color='lime', width=barWidth, edgecolor='white', label='SCORE')
plt.plot(graphNEG, sentSummary.SCORE, color='indigo', linewidth=lineWidth)
plt.xlabel('YEAR', fontweight='bold')
plt.ylabel('SCORE', fontweight='bold')
plt.xticks([r+barWidth for r in range(len(sentSummary.POS))], [text for text in sentSummary.YEAR])
plt.legend()
plt.show()
-
POS, NEG, SCORE 막대의 설정값을 지정해주고(plt.bar), SCORE의 변화를 확인하기 위한 라인그래프 설정값을 정해준다(plt.plot)
- plt.xlabe = x축 레이블 설정, fontweight는 굵게
- plt.ylabe = y축 레이블 설정
- plt.xticks = x축 눈금선 설정
- plt.legend = 범례 설정. 해당 레이블은 각 plt.bar(label=” “)로 설정
- plt.show() 설정이 끝난 후 그래프를 보여주는 명령어
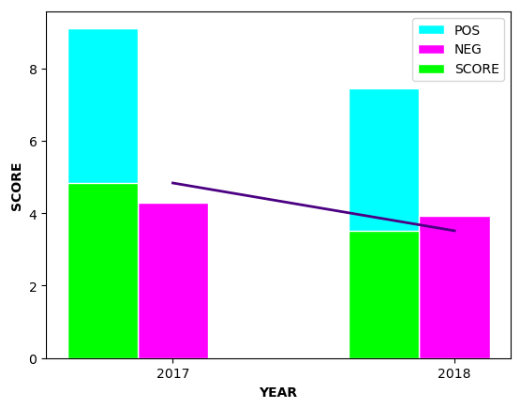
- 여기서 SCORE는 POS-NEG 한 점수이기 때문에 POS막대 그래프와 겹치게 보여주는 방법을 선택했다.
- 이렇게 표현하기 위해선 POS,SCORE의 위치는 같게 NEG의 위치는 POS의 위치에서 barwight(바넓이)만큼 더해주면 된다. 그래서 위와 같은 graphNEG=[x+barWidth for x in graphPOS] 이러한명령문을 사용하여 NEG의 위치를 지정해주었다.
이렇게 감정분석을 통해서 2017년보다 2018년도에 총점이 낮게 나왔는데 부정단어보다는 긍정단어가 적게 측정된 것을 확인할 수 있다.
댓글남기기